문제 상황
https://school.programmers.co.kr/learn/courses/30/lessons/42577
프로그램 제작자
코드 중심 개발자를 고용하십시오. 배치 기반 위치 매칭. 프로그래머의 개발자별 프로필에 가입하고 기술 호환성이 좋은 회사와 연결하십시오.
Programmer.co.kr
접두사가 일치하는 문제 조건에서 사례를 찾으면 false를 반환하도록 지시합니다. 처음 작성한 코드에서는 “접두사” 표현식에 중점을 두고 re 모듈을 사용하여 정규식 비교 코드를 작성했습니다.
import re
def solution(phone_book):
phone_book.sort()
for i in range(0, len(phone_book) - 1):
if re.search(f'^{phone_book(i)}', phone_book(i+1)):
return False
return True이 경우 테스트는 문제 없이 진행되지만 효율 테스트는 실패하는 문제가 있다.
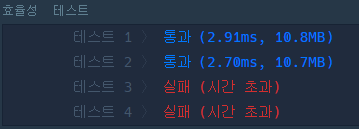
문제의 원인 예측
크게 두 가지 부분에서 문제가 될 수 있는 점들을 생각해 보았다.
- f 문자열이 사용될 때마다 새 문자열이 생성되기 때문입니다.
- re 모듈 내의 re.search 구현에는 비효율적인 기능이 있습니다.
1번의 경우 f-string의 string concatenation 방식이 Python에서 제공하는 string concatenation 방식 중 가장 효율적인 것으로 알려져 있으므로 시간복잡도 측면에서는 문제가 되지 않는다. 이와 관련하여 기사가 작성되었음을 알려드립니다. 공간 복잡도 측면에서 생각해도 파이썬의 가비지 컬렉터는 어쨌든 for 문이 반복되면 할당된 문자열을 해제하므로 메모리 문제는 없다.
따라서 위의 코드가 문제가 되는 원인은 re 모듈 자체에 있는 것으로 판단됩니다. 따라서 re 모듈의 구조를 살펴보기 위해 inspect 모듈로 모듈의 소스 코드를 살펴보았습니다.
re 모듈 작동 방식 살펴보기
Python은 오픈 소스 기반 언어이므로 github에서 내부 구현을 확인할 수 있습니다. 아래 링크를 참조하십시오.
re 모듈의 __init__.py 파일: https://github.com/python/cpython/blob/main/Lib/re/__init__. 파이
import inspect
print(inspect.getsource(re))


re 모듈의 조회 함수는 내부적으로 _compiler 모듈에 정의된 _compile 함수를 사용하여 반환된 객체에 대해 조회 함수를 수행하고 결과 값을 반환합니다.
_compile 함수 정의: https://github.com/python/cpython/blob/main/Lib/re/__init__.py#L280
_compile 함수의 대부분의 동작은 다음과 같습니다. 현금실제 컴파일 프로세스는 _compiler.py, re 모듈의 다른 파일 및 _compile 함수에서 수행됩니다. _compiler.compile 함수에서 반환된 개체를 캐시하는 것 이상을 수행하지 않습니다. 코드에 따르면 _compile 함수는 _cache와 _cache2라는 두 개의 사전을 캐시로 사용하고 크기는 각각 512와 256입니다.
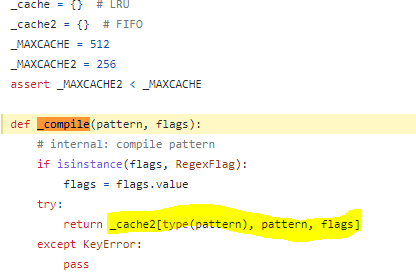
_compiler.compile 함수: https://github.com/python/cpython/blob/main/Lib/re/_compiler.py#L738
_compiler.compile 함수의 경우 정확한 동작 방식을 파악하기 어렵지만, 전송된 패턴을 분석하고 플래그 값을 이용해 플래그 값을 컴파일하여 얻은 객체를 반환한다. 파이썬 공식 문서개체를 정규식 개체(패턴)로 설명하고 개체의 유형은 다음과 같습니다. __init__.py 내부type 함수로 표현됩니다.
이 함수는 내부적으로 _sre라는 모듈을 사용하지만 Python 모듈이 아닌 C언어로 작성되어 있고 re 모듈의 기능을 대부분 수행하는 것으로 알려져 있다. 자세한 구현은 Modules 폴더의 _src 모듈에서 찾을 수 있습니다.
https://github.com/python/cpython/tree/main/Modules/_sre
졸업 증서
위의 정보에서 알 수 있듯이 Re-module 1은 일련의 과정을 거친다. 정규식 개체(패턴) 만들기, 2. __시작__. 두 개의 dict 데이터 유형이 있는 py 파일 은닉처. 캐싱은 여러 개의 동일한 정규식을 자주 사용하지만 현재 문제와 같은 프로그램에 적합할 수 있습니다. 데이터 중복이 발생하지 않는 상황적절한 Regex 개체에서 다시는 사용되지 않는 쓸모없는 메모리 캐싱할 것이다, 캐시 충돌 발생이로 인해 계산 손실이 발생합니다. 캐싱은 일반적으로 전체 비용을 줄이기 위해 수행된다는 점을 고려할 때 정규식 객체를 생성하는 것은 캐싱보다 더 많은 비용이 필요하지만 물론 이 프로세스가 계속됨에 따라 시간을 절약하고 복잡성을 겪을 수 있는 공간 손실이 발생할 수밖에 없습니다.
따라서 이 문제를 해결하려면 re 모듈 대신 간단한 문자열 비교를 수행해야 합니다. 코드는 다음과 같습니다.
def solution(phone_book):
phone_book.sort()
for i in range(0, len(phone_book) - 1):
if phone_book(i) == phone_book(i+1)(:len(phone_book(i))):
return False
return True
# 또는
def solution(phone_book):
phone_book.sort()
for i in range(0, len(phone_book) - 1):
if phone_book(i+1).startswith(phone_book(i)):
return False
return True
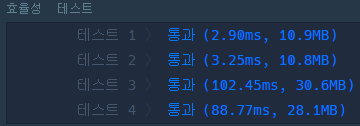
사실 공식 Python re 모듈 문서에는 re 모듈이 캐싱을 수행한다고 언급되어 있지만, 나를 포함한 대부분의 사람들은 인터넷 검색을 통해 간단한 모듈을 사용하는 방법을 배웁니다. re 모듈에서 패턴 객체를 처리하는 모든 함수가 내부적으로 _compile 함수를 호출하여 캐싱 객체가 된다고 되어 있지 않아서 당황스러울 수 있지만, 공식 문서를 읽었다면 이 캔을 닫았을 것입니다. 생각해 보면 공식 문서를 읽는 것보다 모듈을 이해하는 더 좋은 방법은 없는 것 같습니다.